

データ分析基盤の紹介

はじめに
こんにちは。G2 Studios の落合、黒田です。
G2 Studiosのデータ分析基盤について紹介します。
概要を説明後、各コンポーネントについて採用理由や苦労した点などを説明します。
導入背景
G2 Studiosではスマートフォン向けゲームアプリの企画・開発・運営を行っています。
私たちはプロジェクト横断チームとして、ユーザーのゲームの利用状況を分析し、分析結果をサービス展開やイベント企画立案に活用しています。しかし今まではプロジェクト毎に独自の方法で分析や開発をしており、無駄の多い状況でした。そこで、分析業務の属人化の排除、効率化を図るために、データ分析基盤を構築しました。
データ分析基盤の概要
データ分析基盤とは
データ分析の工程を一貫して行うための基盤です。主に以下の機能で構成されます。
・対象となるサービスからログを収集
・生ログデータを貯める「データレイク」
・生データを抽出、クレンジング、加工、出力
・分析用データを保存
・分析ツールで可視化
「データ基盤」と「分析基盤」はそれぞれ下記の意味を指します。
データ基盤
・対象となるサービスからログを収集
・生ログデータを貯めるデータレイク
・生データを抽出、クレンジング、加工、出力
分析基盤
・分析用データを保存
・分析ツールで可視化
構成図
全体の構成図は下図になります。
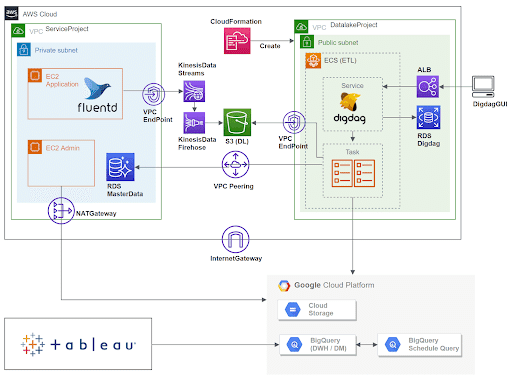
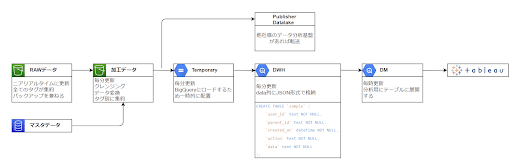
データの処理のおおまかな流れは下図になります。
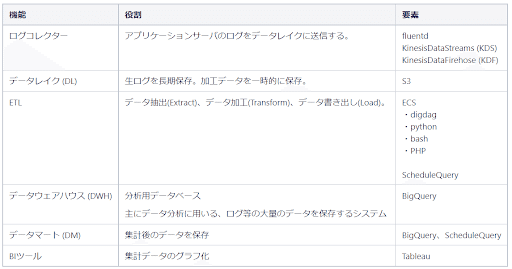
構成要素
データ分析基盤は、以下のコンポーネントで構成されています。
設計するにあたって
データ基盤を設計するにあたって、下記の懸念がありました。
障害発生時に全プロジェクトへの影響
配信タイミングの調整
運用保守コスト
パブリッシャーのデータ分析基盤とのつなぎ込み
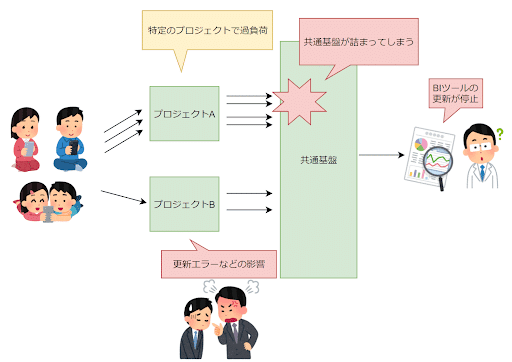
【懸念①:障害発生時に全プロジェクトへの影響】
例えば、特定のプロジェクトで想定以上のトラフィックが発生した場合に共通基盤が詰まり、すべてのプロジェクトに影響が出てしまいます。
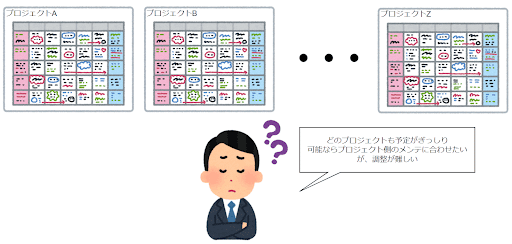
【懸念②:配信タイミングの調整】
システムメンテナンスが必要な作業が発生した場合、全てのプロジェクトで同時刻にシステムメンテナンスに入ることになります。
すべてのプロジェクトとスケジュールを調整することを考えると、コストが高いです。
【懸念③:運用保守コスト】
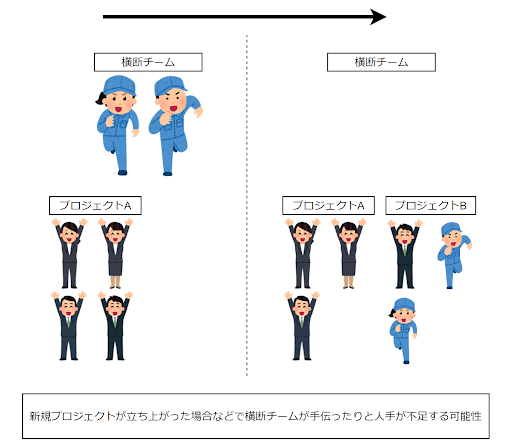
プロジェクト横断チームは、少人数で構成されています。時には、人員が不足しているプロジェクトに参加して、サポートメンバーとして業務を行うこともあります。
共通基盤を長期運用すると様々な問題が発生すると思いますが、早期に解決したくとも人員が不足して長期化してしまう懸念があります。
【懸念④:パブリッシャーのデータ分析基盤とのつなぎ込み】
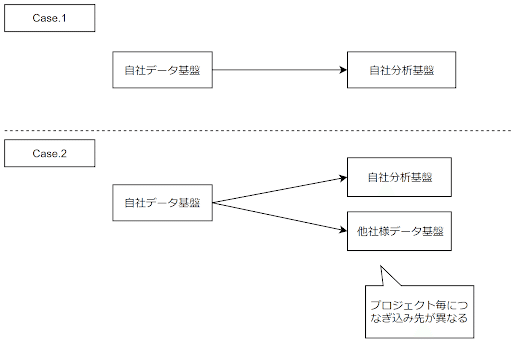
パブリッシャーが運用しているデータ分析基盤へのつなぎ込みを、G2 Studiosのデータ分析基盤でやってほしいとの要望がありました。このような場合、プロジェクト毎につなぎ込み先の切り替えが必要となります。また、プロジェクト毎に新たな要件が増える可能性もあります。
【構築概念】
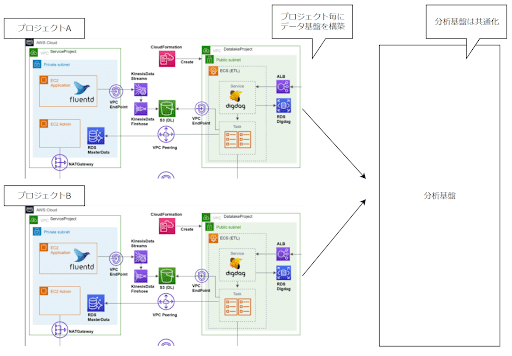
このような事情もあり、共通基盤としてデータ基盤を構築するのではなく、同じシステム構築モデルを使用し、インフラを分離したデータ基盤を構築することにしました。
とはいえ、プロジェクト毎に0から構築していては開発工数が肥大化してしまうため、AWS SAM (CloudFormation)を利用し、テンプレート化することで効率化することにしました。
各コンポーネントについて
各コンポーネントについて、採用理由を紹介します。詳細については長くなるため割愛します。
ログコレクター
ログコレクターは、G2 Studiosで採用実績のあるfluentdを採用しました。
スループット向上とコスト削減のため、Kinesis Producer Library (KPL) を利用してKinesis Data Streams (KDS) に送信するレコードを集約しています。fluentdには、aws-fluent-plugin-kinesisプラグインを導入しています。
Amazon Kinesis プロデューサーライブラリを使用したプロデューサーの開発
KDSをKinesis Data Firehose (KDF) 配信ストリームのソースとして使用することで、集約の解除を行なってくれます。
KPL での Kinesis Data Firehose の使用
プロジェクト側のAPIサーバはPrivateSubnetに配置されているため、通常、NATゲートウェイを経由して外部との通信を行います。
しかし、NATゲートウェイの通信料金は高く、データレイクへのログ送信はデータ量が多いため通信費用が膨れてしまいます。
対策としてVPCエンドポイントを利用し、外部向けの通信を回避することで通信費用を抑えています。
インターフェイス VPC エンドポイントでの Amazon Kinesis Data Streams の使用
データレイクへの通信経路について当初下記の案もありましたが、試算や負荷試験の結果現状の構成となりました。
fluentd → S3
高負荷時にslowdownのエラーが発生。
目標の性能を達成できず、性能向上のためプリフィクスを細分化したら今度はPUTリクエスト数が増えてしまい、PUTリクエスト料金が高額になってしまったため断念。
fluentd → firehose → S3
高負荷時にslowdownのエラーが発生。スロットリングへの対応が必要。
fluentd側でスロットリングへの対応を行うとAPIサーバの負荷となってしまっため、KDSを通し、事前に十分な量のKDSシャードを用意することで対応した。
データレイク
データレイクは、S3を採用しました。
RAWデータを長期保存するのと、ETLタスクで一時的にデータを保存したい場合に利用しています。
下記が採用理由になります。
・プロジェクトでAWSを利用
・高い耐障害性と可用性
・容量無制限
・ライフサイクル設定により、長期保存に適したストレージへ自動的に移行可能
一番の理由は、プロジェクトでAWSを利用しているためです。AWS以外を利用している場合、各社のストレージサービスの利用を検討すると思います。
ログデータを即時調査したい場合は、S3 selectなどを利用してRAWデータを直接参照しています。
ETL
ワークフローエンジンは弊社で採用実績のあるdigdagを採用しました。定期実行、リトライ処理、エラー通知などをdigdagで行っています。
digdagとETLタスクは、ECSFargateで実行しています。digdagからecs run-task コマンドを実行することでECSタスクを起動しています。
データ変換処理のおおまかな流れは下図になります。
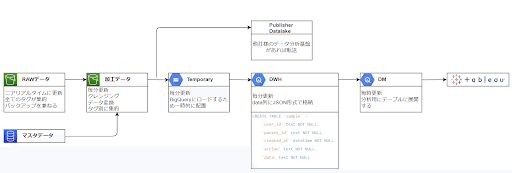
NATを利用するとGCSへの転送料金が高額になるため、PublicSubnetに配置しています。
PublicSubnetに配置するとセキュリティ面で心配になりますが、IAMロールなどの権限付与は最低限にしています。また、セキュリティグループ設定で接続元を絞ることで担保しています。
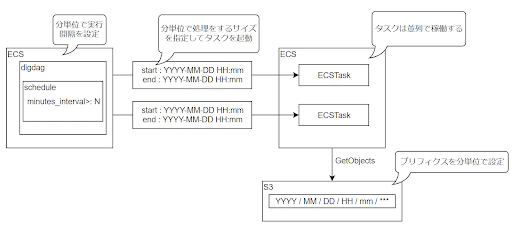
ワークフローのスケジュールについて、「できるだけはやくBIに反映してほしい」との要望があり、dailyでのバッチ処理ではなく分単位でスケジュール設定、処理サイズを調整できるようにしました。
下図のようなイメージで設定をしています。
ETLの設計については紆余曲折ありまして、当初は、StepFunctions、Lambdaを利用していました。
当時の設計だと、ログの量に比例してタスクが長期化していました。タスクが処理中の場合、次のスケジュールのタスクが実行できないように多重実行の制御をする必要がありましたが、StepFunctionsだと多重実行の制御に難があり、digdagを採用することになりました。
現在は分単位ではありますが並列に稼働できるようにしているので、StepFunctionsに戻しても問題はないと考えています。
Lambdaについては、前述の通りタスクの長期化が懸念されるため採用を見送りました。
データウェアハウス/データマート
データウェアハウス及びデータマートに関しては、弊社はBigQueryを採用しています。
BigQueryを利用する利点としては、下記のような点が挙げられます。
・大量のデータの処理能力が高く、ビックデータの分析に優れている
・クエリの自動実行をスケジューリングできる(中間テーブルの自動更新に便利)
BigQuery上でおこなった工夫
① ログのテーブルを取り込み日付別に分けた
ログのAPI実行時の時間別にテーブルを分けることで、クエリ実行時に該当データのスキャン数を軽減し、処理負荷軽減をおこなっています。
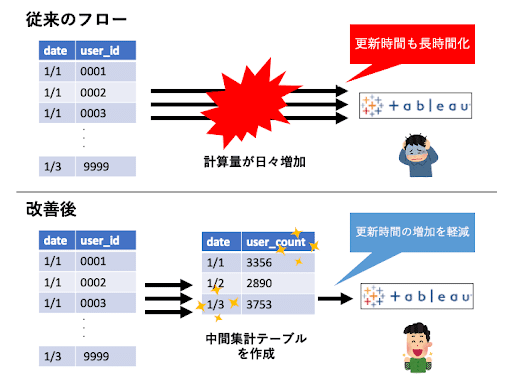
② 過去データの蓄積による処理負荷増加を中間集計にて軽減
運用時の時間経過によるデータ量増加により、BIツールのデータ更新時間も徐々に延長されていく問題が導入初期にはありました。この問題を解決するため、値の集計値を中間テーブルとして作成するように改修を行いました。中間テーブルの作成はBigQuery上のスケジュールクエリの定期実行により、自動的に更新されます。こうして作成した中間テーブルをBIツールで参照するフローに変更したことで、BIツールのデータ更新時間の増加を軽減しています。
③ UDF(ユーザー定義関数)の利用
BigQueryにはUDFという機能があり、利用者自身が定義内容を関数のように使用をすることができます。G2 Studiosでも、中間集計時のクエリに繰り返し利用される『日付の絞り込みの条件』や、『UTC → JST変換』等の処理にUDFを利用し、効率化を行っています。
BIツール
弊社ではBIツール(*1)として、Tableauを利用しています。
Tableauの特徴としては、下記のような点が挙げられます。
・直感的な操作で様々なグラフを作成でき、可視化能力に長けている
・作成したダッシュボード(*2)をTableau Onlineというサービスに反映することで、閲覧者はブラウザ上で確認を行うことができる
・データ更新機能が内蔵されており、指定した時間帯にデータ更新をスケジューリングすることができる
Tableau運用上でおこなっている工夫
導入当初、スマートフォン向けゲームのサービスを運営している特性上、プロジェクト側から「ゲーム内施策の効果等をより早くキャッチアップしたい」という要望が多く寄せられました。
そういった要望に答えるべく、下記のような工夫で処理負荷の軽減を行い、高頻度のデータ更新を実現しました。
・単純な全ログの更新頻度増加は処理負荷がかかるため、データの重要性・必要性の高いものの反映頻度を増やした
・Tableauのデータ更新時、前回取り込み時から差分として増えた箇所のみを取り込む形式に変更をした
*1 BI(ビジネスインテリジェンス)ツール ... 分析したいデータを流し込むことで、集計やグラフによる可視化を行ってくれるツール
*2 ダッシュボード ... BIツールによって作成されたグラフや数値表等をまとめて一覧化したもの
ビルド / デプロイ
ETLについて、AWS SAMで構築しています。
SAMを使用しているのは、当初Lambdaを利用しようとしていたためです。
SAMを使用すると、Lambdaの開発環境をローカルPC上に構築できたり、デプロイを簡易化できます。現在はLambdaではなくECS Fargateを利用していますが、特に問題はないため継続してSAMを使用しています。
ローカルPC上でビルドとデプロイを行っています。
OS間の差異をなくすのと、将来的に移行しやすいようにdocker in dockerの構成にしてあります。
配信先の環境や設定の切り替えは、ホスト側の docker-compose.yml のenv_file設定で行っています。
まとめ
以上、G2 Studiosのデータ分析基盤について紹介させていただきました。導入への参考になりましたら幸いです。
現状安定して稼働はしていますが、仕様変更の名残が残っていたり非効率な処理があったりと、まだまだ改善の余地はありますので、今後も定期的に設計を見直していきます。
G2 Studiosではエンジニアを積極採用中です。
本記事を読んで基盤開発やゲーム開発に興味を持った方は、採用サイトもご覧ください!